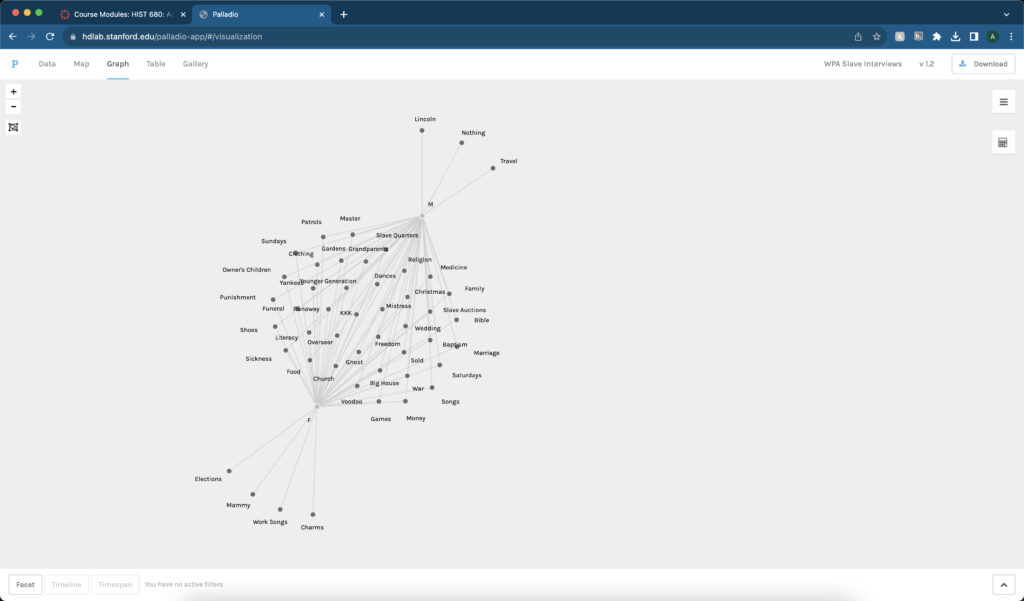
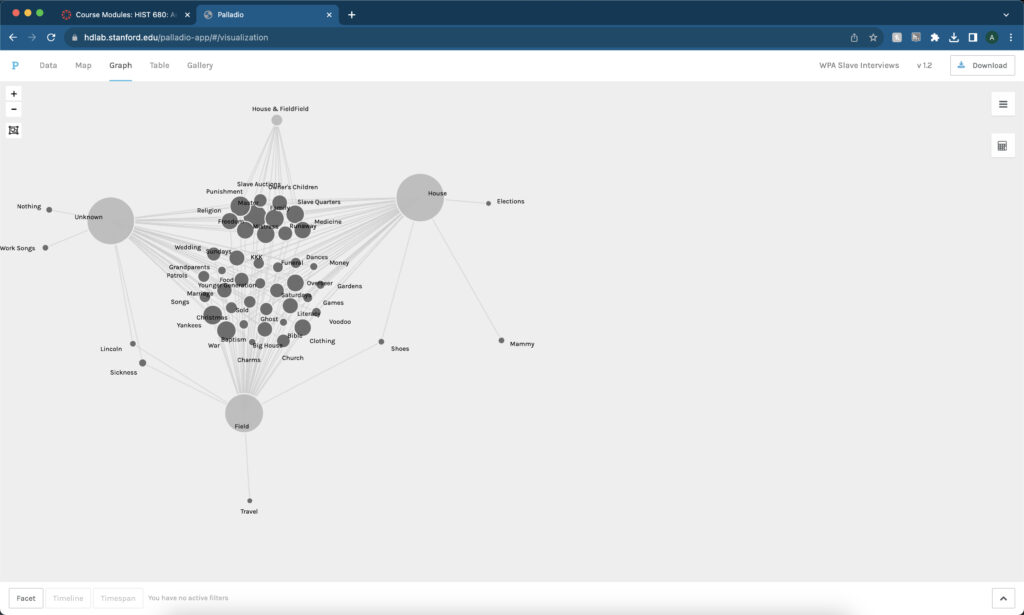
Crowdsourcing is how historians in the Digital Humanities field can create projects that create new ways of analyzing material. Collaborators to The Collective Wisdom Handbook state, “Crowdsourcing can open up new possibilities for research that could not have existed otherwise, fundamentally changing authoritative practices, definitions, and classifications.” (The Collective Wisdom 2) Along with changing the way one analyzes data, there is a component of collaboration. The collaborators on The Collective Wisdom Handbook explain, “At its best, crowdsourcing increases public access to cultural heritage collections while inviting the public to engage deeply with these materials.” (The Collective Wisdom 3) The publics’ collaboration with these projects is one of the main components crowdsourcing. These projects come about in many different ways and what tasks the public undertakes. One of the best examples of these different tasks is transcription.
Transcription in crowdsourcing projects puts the task directly into the public’s hands. The project creators upload documents and ask volunteers to help transcribe them for an online archive. One of the first projects to bring this idea forward was Transcribe Bentham. The Transcribe Bentham project uses documents created by philosopher Jeremy Bentham “with the intention of engaging the public with Bentham’s thought and works, creating a searchable digital repository of the collection, and quickening the pace of transcription and publication by recruiting unpaid online volunteers to assist in transcribing the remaining manuscripts.” (Causer, Tonra, and Wallace, Transcription maximized, 120) The project aims to have volunteers transcribe the documents that creators upload in a collaborative effort to build an archive of Bentham’s documents.
Another project that uses transcription in a crowdsourcing project is By the People. By the People is a project created by the Library of Congress, designed similarly to Transcribe Bentham, that encourages volunteers to help transcribe documents uploaded to create an archive. The documents in this project vary widely “into ‘Campaigns’ and presented to volunteers along with transcription conventions, a discussion platform, and explanatory material to help folks learn a bit about the subjects of the documents.” (Hyning and Jones, Data’s Destinations, 9) This learning of the material is how these projects keep participants engaged in transcribing the documents. With Transcribe Bentham, the creators discovered that volunteers “were motivated by a sense of contributing to the greater good by contributing to the production of the Collected Works and making available Bentham’s writings to others, whereas some even found transcribing fun.” (Causer, Tonra, and Wallace, Transcription maximized, 127) To keep volunteers excited and engaged to transcribing the material, they need to feel like they play a significant factor in the process and it has to be fun.